This is my first post of a series which will cover how you can distribute your OpenShift cluster across multiple datacenter domains and increase availability and performance of your control plane.
Background
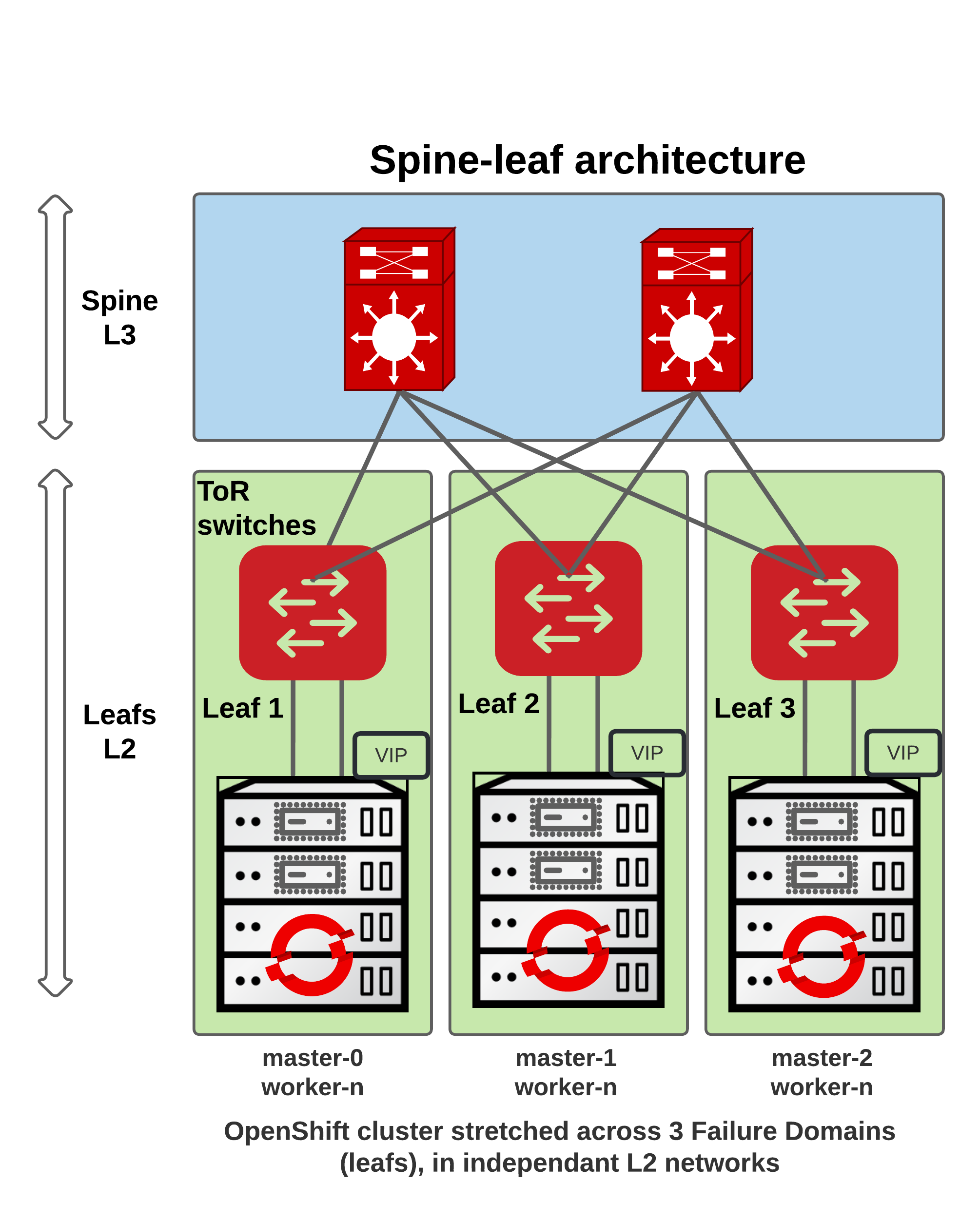
Originally the on-premise OpenShift IPI architecture was designed to deploy an internal (called OpenShift Managed) load balancer based on HAproxy and Keepalived. However when you want to distribute your cluster across multiple failure domains, your control plane has to be deployable on multiple L2 networks, which are usually isolated per rack, and routed with protocols like BGP.
Stretched vs L3 networks
A single stretched L2 network brings challenges:
- Network latency is not predictable
- Traffic bottlenecks
- L2 domain failures
- Network management complexity
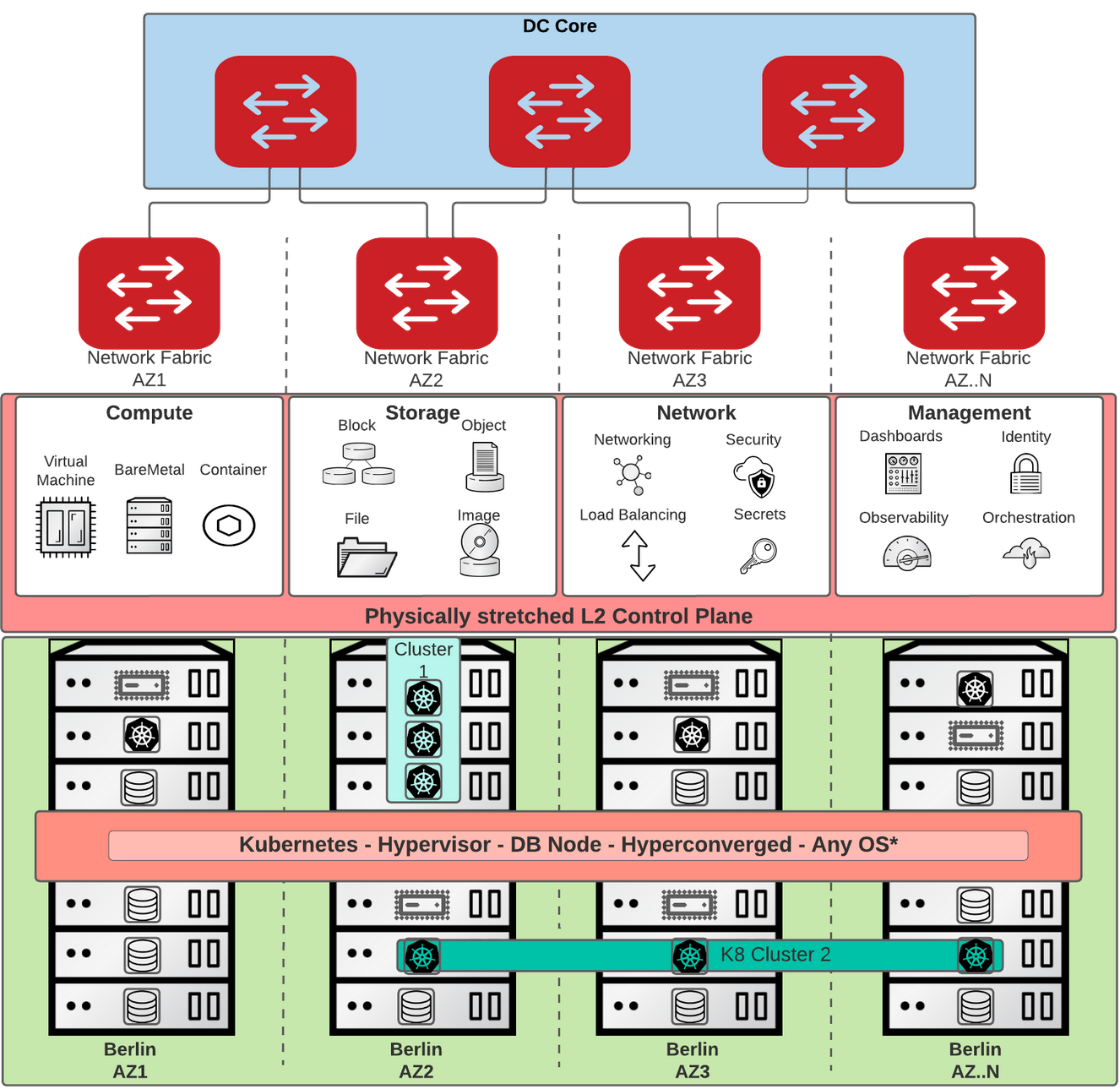
Smaller (L3 routed) networks however has these benefits:
- Optimize East-West traffic
- Low and predictable latency
- Easier to extend and manage
- Failure domain isolated to a network
- Non blocking network fabric
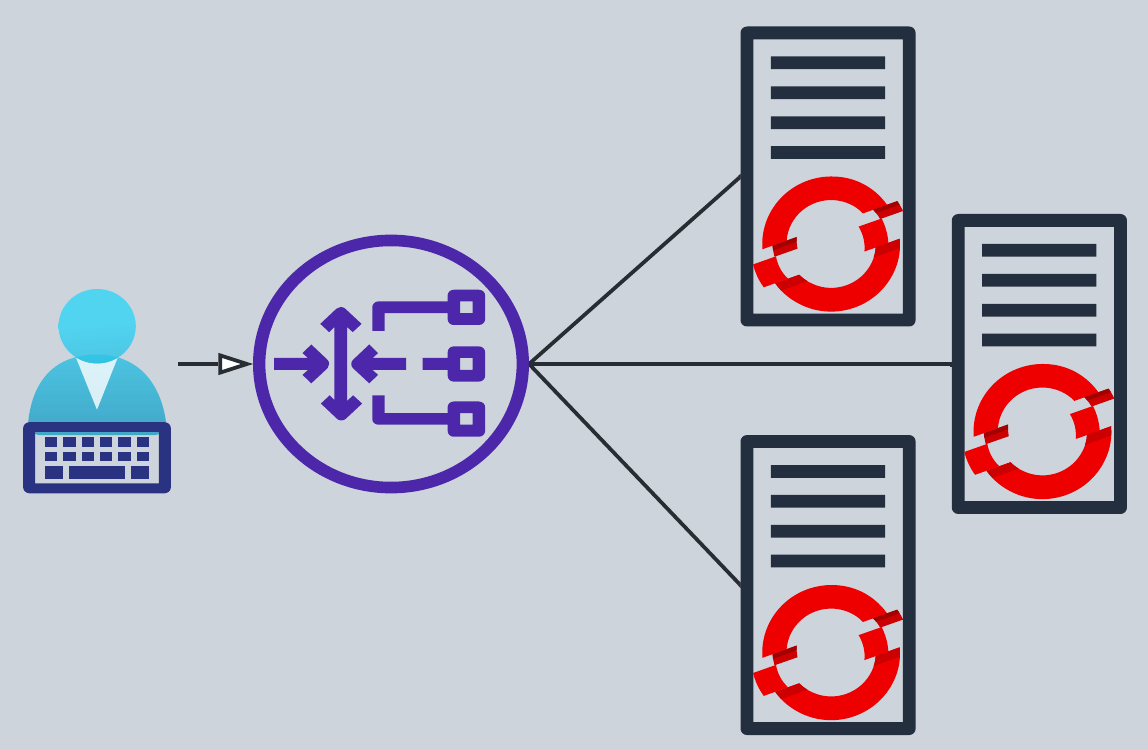
OpenShift Managed Load-Balancer
For on-prem platforms (VSphere, Baremetal, OpenStack, Ovirt and Nutanix), the control plane load balancer is based on HAproxy and Keepalived. It means that the control plane VIPs (for API & Ingress services) will be managed in Active/Passive mode. The Keepalived master (elected by VRRPv2) will host the VIPs and therefore all the API & Ingress traffic will always go through one node and then load-balanced across the control plane. This bottleneck has been an issue at large scale.
Also, Keepalived doesn’t deal with L3 routing, so if the VIPs aren’t within the same subnet as the L2 networks, the network fabric can’t know where the VIPs actually are.
User Managed Load-Balancer
When we initially looked at the limitations of the OpenShift Managed Load-Balancer, we thought we would just add BGP to the OpenShift control plane, so the VIPs could be routed across the datacenter. You can have a look at this demo that shows how it would work. After the initial proposal which brought up a lot of good ideas, it was decided that for now we would rather try to externalize the Load-Balancer and let the customers dealing with it, rather than implementing something new in OpenShift (I’ll come back to it the wrap-up).
Indeed, a lot of our customers already have (enterprise-grade) load balancers that they use for their workloads. Some of them want to re-use these appliances and manage the OpenShift control plane traffic with them.
We realized that some of them want BGP, some of them don’t. Some want to keep stretched L2 networks, some don’t. There were a lot of decisions we would make if we would have implemented BGP within the OpenShift control plane so we decided that for now we will allow to use an external (user-managed) load balancer, like it’s already the case for the workloads themselves (e.g. with MetalLB).
More details on the design can be found in this OpenShift enhancement.
Deploy your own Load-Balancer
I want to share how someone can deploy a load balancer that will be used by the OpenShift control plane. For that, I’ve decided to create an Ansible role named ansible-role-routed-lb.
This will deploy an advanced Load-Balancer capable of managing routed VIPs with FRR (using BGP) and load-balance traffic with HAproxy.
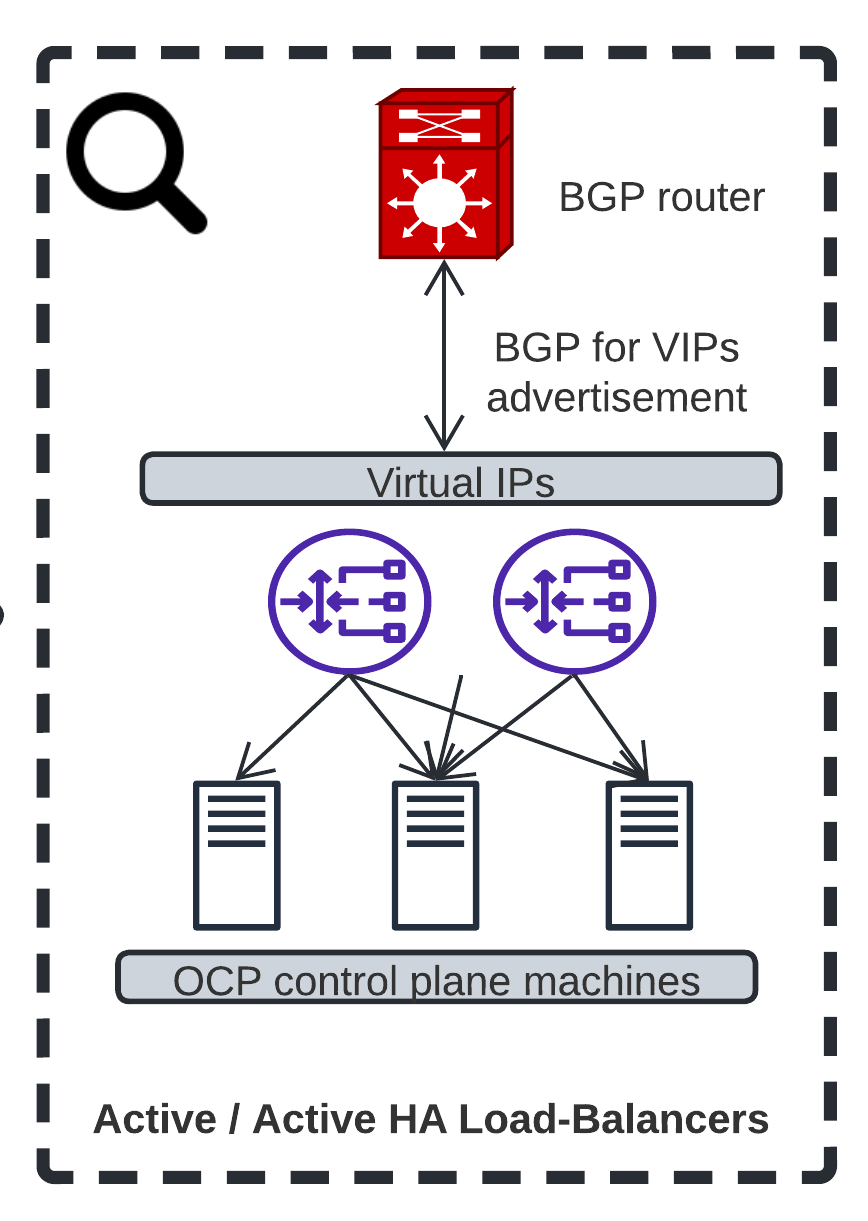
The role will do the following:
- If BGP neighbors are provided in the config, it’ll deploy FRR and peer with your BGP neighbor(s). If the VIPs are created on the node, they’ll be routed in your infrastructure.
- Deploy HAproxy to load-balance and monitor your service. If the VIPs are provided in the config, they will be created if a minimum number of backend(s) are found healthy for a given service, and therefore routed in BGP if FRR is deployed. They will be removed if no backend was found healthy for a given service, therefore not routed in BGP if FRR is deployed
So if you’re hosting multiple Load-Balancers, your OpenShift control plane traffic will be:
- routed thanks to BGP if FRR is deployed
- load-balanced and high-availability at the VIP level thanks to BGP if FRR is deployed
- load-balanced between healthy backends thanks to HAproxy
Let’s deploy it!
In this blog post, we won’t cover the Failure Domains yet, and will deploy OpenShift within a single Leaf. Therefore, we’ll deploy only one load balancer.
Create your Ansible inventory.yaml file:
---
all:
hosts:
lb:
ansible_host: 192.168.11.2
ansible_user: cloud-user
ansible_become: true
192.168.11.2 is the IP address of the load balancer.
Create the Ansible playbook.yaml file:
---
- hosts: lb
vars:
config: lb
tasks:
- name: Deploy the LBs
include_role:
name: emilienm.routed_lb
Write the LB configs in Ansible vars.yaml:
---
configs:
lb:
bgp_asn: 64998
bgp_neighbors:
- ip: 192.168.11.1
password: f00barZ
services:
- name: api
vips:
- 192.168.100.240
min_backends: 1
healthcheck: "httpchk GET /readyz HTTP/1.0"
balance: roundrobin
frontend_port: 6443
haproxy_monitor_port: 8081
backend_opts: "check check-ssl inter 1s fall 2 rise 3 verify none"
backend_port: 6443
backend_hosts: &lb_hosts
- name: rack1-10
ip: 192.168.11.10
- name: rack1-11
ip: 192.168.11.11
- name: rack1-12
ip: 192.168.11.12
- name: rack1-13
ip: 192.168.11.13
- name: rack1-14
ip: 192.168.11.14
- name: rack1-15
ip: 192.168.11.15
- name: rack1-16
ip: 192.168.11.16
- name: rack1-17
ip: 192.168.11.17
- name: rack1-18
ip: 192.168.11.18
- name: rack1-19
ip: 192.168.11.19
- name: rack1-20
ip: 192.168.11.20
- name: ingress_http
vips:
- 192.168.100.250
min_backends: 1
healthcheck: "httpchk GET /healthz/ready HTTP/1.0"
frontend_port: 80
haproxy_monitor_port: 8082
balance: roundrobin
backend_opts: "check check-ssl port 1936 inter 1s fall 2 rise 3 verify none"
backend_port: 80
backend_hosts: *lb_hosts
- name: ingress_https
vips:
- 192.168.100.250
min_backends: 1
healthcheck: "httpchk GET /healthz/ready HTTP/1.0"
frontend_port: 443
haproxy_monitor_port: 8083
balance: roundrobin
backend_opts: "check check-ssl port 1936 inter 1s fall 2 rise 3 verify none"
backend_port: 443
backend_hosts: *lb_hosts
- name: mcs
vips:
- 192.168.100.240
min_backends: 1
frontend_port: 22623
haproxy_monitor_port: 8084
balance: roundrobin
backend_opts: "check check-ssl inter 5s fall 2 rise 3 verify none"
backend_port: 22623
backend_hosts: *lb_hosts
In this case, we deploy OpenShift on OpenStack which doesn’t support static IPs. Therefore, we have to put all the available IPs from the subnet used for the machines, in the HAproxy backends.
Install the role and the dependencies:
ansible-galaxy install emilienm.routed_lb,1.0.0
ansible-galaxy collection install ansible.posix ansible.utils
Deploy the LBs:
ansible-playbook -i inventory.yaml -e "@vars.yaml" playbook.yaml
Deploy OpenShift
This feature will be available in the 4.13 release as TechPreview.
Here is how you can simply enable it via the install-config.yaml:
apiVersion: v1
baseDomain: mydomain.test
compute:
- name: worker
platform:
openstack:
type: m1.xlarge
replicas: 3
controlPlane:
name: master
platform:
openstack:
type: m1.xlarge
replicas: 3
metadata:
name: mycluster
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 192.168.11.0/24
- cidr: 192.168.100.0/24
platform:
openstack:
cloud: mycloud
machinesSubnet: 8586bf1a-cc3c-4d40-bdf6-c243decc603a
apiVIPs:
- 192.168.100.240
ingressVIPs:
- 192.168.100.250
loadBalancer:
type: UserManaged
featureSet: TechPreviewNoUpgrade
You can also watch this demo which shows the outcome.
Known limitations
- Deploying OpenShift with static IPs for the machines is only supported on Baremetal platform for now but it’s in the roadmap to support it on VSphere and OpenStack as well.
- Changing the IP address for any OpenShift control plane VIP (API + Ingress) is currently not supported. So once the external LB and the OpenShift cluster is deployed, the VIPs can’t be changed. This is in our roadmap.
- Migrating an OpenShift cluster from the OpenShift managed LB to an external LB is currently not supported. It’s in our roadmap as well.
Keep in mind that the feature will be TechPreview at first and once it has reached some maturity, we’ll promote it to GA.
Wrap-up
Having the VIPs highly available, routed across multiple domains is only a first step into distributing the OpenShift control plane. In the future, we’ll discuss about how Failure Domains will be configured when deploying OpenShift on OpenStack. Note that this is already doable on Baremetal and Vsphere.
With this effort, our customers can now decide which Load-Balancer to use, and if they have some expertise in their appliance now they can use it for the OpenShift control plane.
The way we implemented it is flexible and will allow us to implement new load balancers in OpenShift if we want to in the future. The proof of concept done a few months ago with BGP in the control plane could be restored if there is growing interest.
I hope you liked this article and stay tuned for the next ones!